设计规范
✨:建表的时候需要注意 🌟:查询,日常代码编写的时候 ⭐:难度
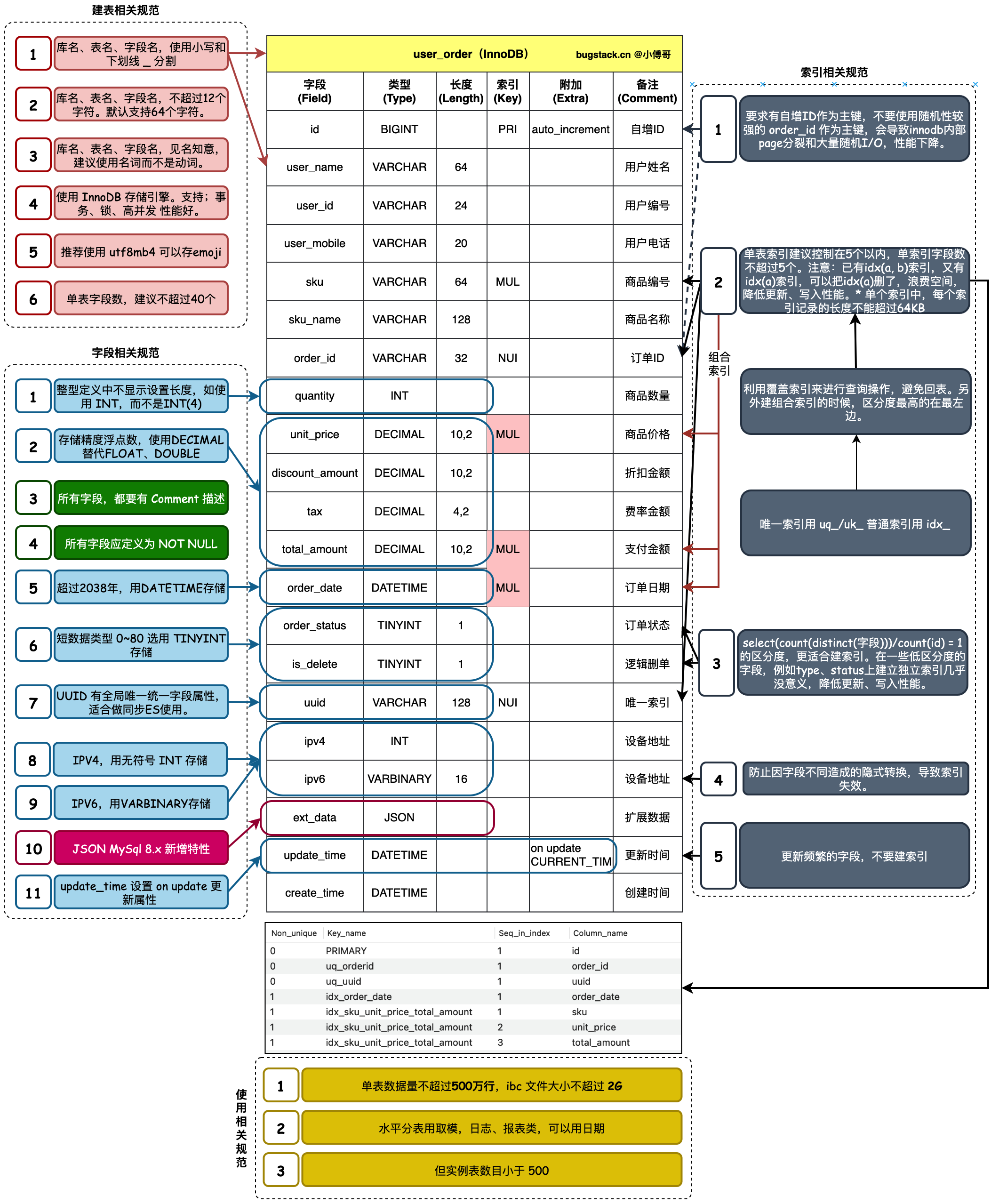
1. 建表相关规范(⭐)
- 1.库名、表名、字段名,使用小写和下划线 _ 分割。✨
- 2.库名、表名、字段名,不超过12个字符。默认支持64个字符。✨
- 3.库名、表名、字段名,见名知意,建议使用名词而不是动词。✨
- 4.使用 InnoDB 存储引擎。支持;事务、锁、高并发 性能好。✨
- 5.推荐使用 utf8mb4 可以存emoji。✨
- 6.单表字段数,建议不超过40个。✨
2. 字段相关规范(⭐)
- 1.整型定义中不显示设置长度,如使用 INT,而不是INT(4) (无意义)✨
- 2.存储精度浮点数,使用 DECIMAL 替代 FLOAT、DOUBLE(避免精度丢失)✨
- 3.所有字段,都要有 Comment 描述✨
- 4.所有字段应定义为 NOT NULL✨
- 5.超过2038年,用DATETIME存储(DATESTAMP只到2038)✨
- 6.短数据类型 0~80 选用 TINYINT 存储✨
- 7.UUID 有全局唯一统一字段属性,适合做同步ES使用。✨
- 8.IPV4,用无符号 INT 存储(INT UNSIGNED(INET_ATO()))✨
- 9.IPV6,用VARBINARY存储(VARBINARY(16))✨
- 10.JSON MySql 8.x 新增特性✨
- 11.update_time 设置 on update 更新属性(设置ON UPDATE CURRENT_TIMESTAMP)✨
3. 索引相关规范
- 1.要求有自增ID作为主键,不要使用随机性较强的 order_id 作为主键,会导致innodb内部page分裂和大量随机I/O,性能下降。(避免随机主键如 UUID 导致页分裂)✨
- 2.单表索引建议控制在5个以内,单索引字段数不超过5个。注意:已有idx(a, b)索引,又有idx(a)索引,可以把idx(a)删了,浪费空间,降低更新、写入性能。单个索引中,每个索引记录的长度不能超过64KB。(单表索引和单索引字段数≤ 5 | 避免冗余索引)✨
- 3.利用覆盖索引来进行查询操作,避免回表。另外建组合索引的时候,区分度最高的在最左边。(覆盖索引 | 最左前缀原则)🌟
- 4.
select(count(distinct(字段)))/count(id) = 1的区分度,更适合建索引。在一些低区分度的字段,例如type、status上建立独立索引几乎没意义,降低更新、写入性能。(低区分度字段(如status)不适合单独建索引)✨ - 5.防止因字段不同造成的隐式转换,导致索引失效。(禁止索引失效操作)🌟
- 6.更新频繁的字段,不要建索引。✨
4. 使用相关规范
- 1.单表数据量不超过500万行,ibc 文件大小不超过 2G (容易引发性能问题(如慢查询、索引失效、备份变慢))
- 2.水平分表用取模,日志、报表类,可以用日期
- 3.单实例表数目小于 500(会拖慢information_schema查询,导致元数据管理和权限加载变慢)
- 4.alter表之前,先判断表数据量,对于超过100W行记录的表进行alter table,必须在业务低峰期执行。因为alter table会产生表锁,期间阻塞对于该表的所有写入(写入会被阻塞)
- 5.SELECT语句必须指定具体字段名称,禁止写成
“*”select *会将不需要读的数据也从MySQL里读出来,造成网卡压力,数据表字段一旦更新,但model层没有来得及更新的话,系统会报错(增加网络和内存负担、可读性差,不利于代码维护和字段追踪) - 6.insert语句指定具体字段名称,不要写成
insert into t1 values(…)(防止字段顺序变更导致插入错误,可读性更高,避免遗漏或错位) - 7.
insert into…values(XX),(XX),(XX)..这里XX的值不要超过5000个,值过多会引起主从同步延迟变大。(占用大量内存,导致主从延迟) - 8.
union all和union,不要超过5个子句,如果没有去重的需求,使用union all性能更好。(UNION需要去重操作(排序+比较),UNINO ALL 不去重,性能好) - 9.in 值列表限制在500以内,例如
select… where userid in(….500个以内…),可以减少底层扫描,减轻数据库压力。(实际上是多个OR操作,大量值会导致索引失效或扫描变慢) - 10.除静态表或小表(100行以内),DML语句必须有where条件,且尽量使用索引查找(防止误删/更新全表数据、快速定位,避免全表扫描)
- 11.生产环境禁止使用 hint,如 sql_no_cache,force index,ignore key,straight join等。 要相信MySQL优化器。hint是用来强制SQL按照某个执行计划来执行,但随着数据量变化我们无法保证自己当初的预判是正确的。
- 12.where条件里,等号左右字段类型必须一致,否则会造成隐式的类型转化,可能导致无法使用索引(类型不一致会导致MySQL隐式转换,如int=‘100’会转换类型,可能导致索引失效;可通过explain检查是否使用了索引)
- 13.生产数据库中强烈不推荐在大表执行全表扫描,查询数据量不要超过表行数的25%,否则可能导致无法使用索引(查询数据量过大,MySQL判断不如全表扫描划算,导致不走索引)
- 14.where子句中禁止只使用全模糊的LIKE条件进行查找,如like ‘%abc%’,必须有其他等值或范围查询条件,否则可能导致无法使用索引(前缀模糊无法使用索引)
- 15.索引列不要使用函数或表达式,如
where length(name)=10或where user_id+2=1002,否则可能导致无法使用索引(MySQL在执行前对字段处理一遍,失去索引使用机会) - 16.减少使用or语句 or有可能被 mysql优化为支持索引,但也要损耗 mysql 的 cpu 性能。可将or语句优化为union,然后在各个where条件上建立索引。如
where a=1 or b=2优化为where a=1… union …where b=2, key(a),key(b)某些场景下,也可优化为in - 17.分页查询,当limit起点较高时,可先用过滤条件进行过滤。如
select a,b,c from t1 limit 10000,20; 优化为select a,b,c from t1 where id>10000 limit 20;(前者会先扫描前10万行再取后20行;后者会跳过扫描) - 18.同表的字段增删、索引增删等,合并成一条DDL语句执行,提高执行效率,减少与数据库的交互。(合并表结构变更的DDL,最好一次性完成)
- 19.
replace into和insert on duplicate key update在并发环境下执行都可能产生死锁(后者在5.6版本可能不报错,但数据有可能产生问题),需要catch异常,做事务回滚,具体的锁冲突可以关注next key lock和insert intention lock - 20.TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少,但 TRUNCATE 无事务且不触发 trigger ,有可能造成事故,故不建议在开发代码中使用此语句。说明: TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE 语句相同。